


Does a Pattern-Based DW Architecture Still Hold Value Today? (Part 3 of 4)
By Cynthia Meyersohn
Picking up from Part 2 of this series where we left off having replicated the data a minimum of nine times, we will continue to identify additional data replication stages as we trace through the data processes outlined in “Build a Schema-On-Read Analytics Pipeline Using Amazon Athena”, by Ujjwal Ratan, Sep. 29, 2017, on the AWS Big Data Blog, https://aws.amazon.com/blogs/big-data/build-a-schema-on-read-analytics-pipeline-using-amazon-athena/ (Ratan, 2017).
Keep in mind that my series of articles is following the breakdown of the AWS Schema-on-Read analytics pipeline with a focus on data movement and replication to answer the question, “Does the size of the data now being delivered to the business make a compelling argument that the data should not be moved around as much?” I believe one of our goals should be to reduce the number of times volumes of data are moved around or replicated.
Continued from Step 3 – Reporting table …
Step 4 – Amazon QuickSight dashboard
Finally, with the data separated into a number of different results files (.csv) located in a separate S3 bucket, the data is ready to be read into the Athena “table” for reporting. Let’s hope that every one of the three query outputs are identical in format and layout, otherwise you’re building three different reporting definitions, one for each layout.
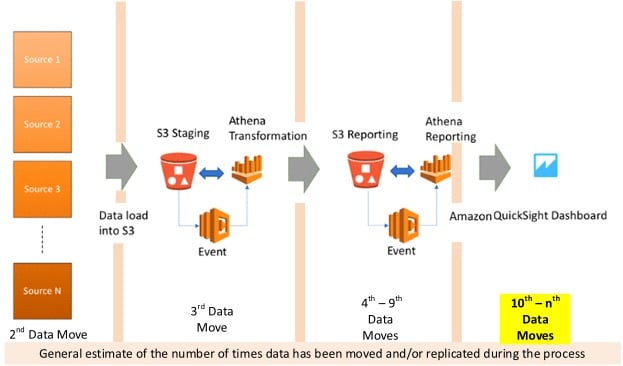
Fortunately, in the author’s example, all three queries produce the same layout – meaning it’s a single Athena “table”.
Step 5 – Incremental data ingestion
Last but not least, the author addresses incremental data loads. Really? … at the end of the process you’re going to figure out how to maintain the data for operational continuity? Shouldn’t that have been planned at Step 1? Maybe that’s something the architect should have considered in his initial design, but apparently incremental loads/operational continuity didn’t make the cut for the set of “important criteria” that must be considered when designing an analytical platform …
So, because the incremental or ongoing ingest process wasn’t planned upfront, and therefore, is not pattern-based or repeatable; new ETL processes must be written to ingest incremental data and refresh all the data as it moves up the chain to the reporting tables. That doesn’t strike me as a sustainable process, and why are those incremental processes so different from the initial load processes that they have to be separate?
As a matter of fact, the incremental load processes seem much more complex than the initial load processes. It is quite possible that the complexity of these incremental processes is attributable to the limitations in delta processing available in a PSA. Add to the complexity of these incremental processes what appears to be exponential data replication. The data has now moved 10+ times.
Why are we doing this? Doesn’t virtualization (creating a view) do the same thing without replicating the data? How is this at all sustainable or an improvement?
# of Data Movements in AWS – exponential!!!
Mr. Ratan’s Conclusion
To save his bacon (so to speak), the author adds this statement in his conclusion, “However, it’s important to note that a schema-on-read analytical pipeline may not be the answer for all use cases. Carefully consider the choices between schema-on-read and schema-on-write.” (Ratan, 2017)
Seriously … you think so? His article should have started with these statements.
Per Mr. Ratan, if –
(1) systems have defined data structures (like the one that generated all of the .csv files in the first place!), or
(2) utilize target queries that mostly involve joins across normalized tables (umm, like probably 90% of all data warehouses), or
(3) you are using fixed dashboards with little to no changes (why is this even relevant?)
… then a schema-on-write is probably a better solution for query performance!!!
Now, all sarcasm aside, if Mr. Ratan had used data that was originally sourced in a JSON format (meaning, it was not generated from a structured database and output in JSON format), and had built his example around such a data set, I might have been less critical because those are challenging dilemmas that the industry is facing (unless, of course, you’re on Snowflake DB). But he didn’t.
The Zinger
My challenges to the concepts in Mr. Ratan’s article are quite simple.
The analogy the author starts with is based on the healthcare industry. A dangerous industry to select as a subject area (I would think) due to the issues of managing data privacy, governance, security, and auditability inherent in the realm of healthcare data. Here are the questions that I believe IT managers and C-level executives should be asking themselves when considering “Data Lake” technologies.
Notwithstanding the fact that the author’s particular set of selected data did not appear to contain Protected Health Information (PHI), here goes …
- What happens when all of this data is called in for an audit? How do you audit an exponential number of data files and trace them through their various states (transformations) back to the source system or systems? Seems like an absolute nightmare to me.
Where in the AWS Glue Data Catalog are the record source or transformation rules stored, and to what level of detail are those pieces of critical information identified? I admit, I’ve only done a cursory review of the AWS Glue Data Catalog’s capabilities. However, having said this I would be somewhat surprised if AWS Glue Data Catalog stored the custom metadata and metaprocesses to the level of detail required along with the schema-on-read definitions.
Hopefully, I’m wrong …
- If the data were to include PHI, how is the PHI secured at rest? In motion? In the author’s example, the .csv files have been proliferated across at least two S3 buckets. Would PHI be stored and sorted into separate, secured S3 buckets?
Let’s say PHI is stored in separate S3 buckets for security reasons. This implies that the data is potentially proliferated into two additional S3 buckets (bringing us to a total of four S3 buckets).
If PHI data is split out from the non-PHI data, a business key is going to be required to join the data back together. Maybe Athena’s schema-on-read table definitions can handle this, but it’s a schema-on-read which now has to span multiple S3 buckets across a plethora of files.
I don’t know about you, but I don’t see performance getting much better at this order of magnitude.
- How do you prove compliance in this environment? It can’t be simple … and oh, by the way, how do you prove that no AWS technical support staff are able to access your S3 buckets? I’m sure there is a way to secure AWS S3 because the Intelligence Community (IC) is using a secured AWS Cloud environment; however, that’s in the IC’s private Cloud.
What about the rest of the world?
- Let’s introduce into this mix (or mess, depending upon your perspective) the General Data Protection Regulation (GDPR) passed by the EU in 14 April 2016 with full compliance required by 25 May 2018. How does a business comply with GDPR and prove compliance? The data has already been replicated exponentially.
According to GDPR, companies have to delete or irreversibly anonymize specific records based on a living individual’s request to purge their data from all databases under the company’s control wherever the data exists. You can’t just mask it, you have to delete it or irreversibly anonymize it … everywhere.
Admittedly, I’m not an AWS guru … but in some AWS environments teams are still struggling with what it takes to secure data appropriately, grant the right level of permissions (to tools, individuals, and discrete data elements), and still keep costs down.
In my final article, Part 4 of this series, I will talk about what I believe is a solid technical approach through which to implement a “Data Lake” that will provide the true business value that companies are hoping to receive.
References used throughout this series –
AWS. (2018, July 20). index. Retrieved from Amazon Web Services: https://aws.amazon.com/what-is-aws/
Cole, D. (2014). http://www.nybooks.com/daily/2014/05/10/we-kill-people-based-metadata/. Retrieved from http://www.nybooks.com: http://www.nybooks.com/daily/2014/05/10/we-kill-people-based-metadata/
Commission, E. (n.d.). https://ec.europa.eu/info/law/law-topic/data-protection/reform/what-personal-data_en. Retrieved from https://ec.europa.eu/info/index_en: https://ec.europa.eu/info/law/law-topic/data-protection/reform/what-personal-data_en
Ho. Jason Chaffetz, H. M. (2016). OPM Data Breach: How the Government Jeopardized Our National Security for More than a Generation. Washington D.C.: Committee on Oversight and Government Reform – U.S. House of Representatives – 114th Congress.
Inmon, W. (2016). Data Lake Architecture Designing the Data Lake and Avoiding the Garbage Dump. (R. A. Peters, Ed.) Basking Ridge, NJ, USA: Technics Publications.
Linstedt, D. (2016). Building a Scalable Data Warehouse with Data Vault 2.0. Waltham: Todd Green.
Linstedt, D. (2018, May). Data Vault 2.0 Architecture Diagram. Data Vault 2.0 Boot Camp & Private Certification.
Ratan, U. (2017, Sep 29). AWS Big Data Blog. Retrieved from https://aws.amazon.com: https://aws.amazon.com/blogs/big-data/build-a-schema-on-read-analytics-pipeline-using-amazon-athena/




