

Relationships:Becoming a Data Driven Data Warehouse
Too many consultancies provide the following advice: Model your data warehouse with source system relationships, maintain source system referential integrity. In this article we will explore why: a) this is really bad advice, and b) leads to a rigid data warehouse requiring re-engineering when loading a new source. If you want to build a data driven warehouse then your team must understand the following paradigm: all expressed source application relationships are business rules that change over time.
If you think this is just a technical post, please be patient and read through it thoroughly. This is as much about business and business debt as it is about a specific solution or reason why we design data warehouses with many-to-many relationships…
Data Vault Modeling has been accused of a bad design idea: changing all your source relationships to many-to-many relationships in your data warehouse. We will explore why this is a false accusation, and more importantly: understand why this is the only way to build a resilient, future proof data driven data warehouse solution. This article will not dive in to the technical details of how to do this, but rather will focus on the concept of relationships, what they are, and why Data Vault chooses many-to-many for its’ design paradigm.
Understanding Source System Relationships
To understand the problem, as well as the solution we need to first understand how relationships are expressed in operational source systems. Simplified for anyone performing BI and analytics on their business data.
- One-To-One: In mathematics, an injective function is a function that maps distinct elements of its domain to distinct elements of its co domain. In other words, every element of the function’s co-domain is the image of at most one element of its domain. https://en.wikipedia.org/wiki/Injective_function. in Data Modeling, Exactly ONE employee can manage EXACTLY ONE Department for a single point in time. It also has a data modeling definition which mirrors the mathematical one: https://en.wikipedia.org/wiki/One-to-one_(data_model)
- One-To-Many: In systems analysis, a one-to-many relationship is a type of cardinality that refers to the relationship between two entities (see also entity–relationship model) https://en.wikipedia.org/wiki/One-to-many_(data_model) . In Data Modeling: ONE Book may have MANY pages
- Many-to-One: A reverse of One-To-Many. An example may be: Many employees manage a SINGLE department.
- Many-To-Many: In systems analysis, a many-to-many relationship is a type of cardinality that refers to the relationship between two entities[1] A and B in which A may contain a parent instance for which there are many children in B and vice versa. https://en.wikipedia.org/wiki/Many-to-many_(data_model) An Example may be: A book can have many authors, but a single author can ALSO author many books.
Why is This Important?
Before we get going, I have some questions for you as a business user, or a technical business user… These questions relate to the types of outcomes you might want your data warehouse to provide (regardless of whether or not it’s a Data Vault Model)…
- don’t you think it’s just as important that a Data Warehouse identify the technical debt as it is to provide proper clean analytics?
- What about a data warehouse that also identifies broken business processes?
- Shouldn’t it tell you when the data its collecting does not match your expectations of what your business needs to do?
- What if you have multiple operational applications that should synchronize to each other, but DON’T. Wouldn’t you want to know about these as well?
Real-World Examples
Before you say: Those questions don’t matter, or dirty data doesn’t cause problems, or my business processes all work, or my operational system is GOOD… let me elaborate with a few examples from my real-world experience: Let’s put these questions another way (these are all examples of broken and bad data that I personally experienced at Lockheed Martin on an enterprise scale). These are questions that Lockheed asked the data warehouse that we built:
- Which contracts have Employees working on them, but have no contract numbers? IF we had enforced relationships in the warehouse, we never would have brought the data in, so we could never have built data driven BI reports showing metrics about contracts that don’t have contract numbers. The operational application had broken business logic that allowed this data to be created, but yet never queried (could not be edited).
- Which work-centers have work done, but aren’t defined in the operational system? Turns out, accounting had created VIRTUAL work centers -for charge-backs that the rest of the business didn’t know about until we exposed them, until we loaded the accounting systems source data. The accounting system had copies of the data and, the relationship expressed differently than the manufacturing and planning systems.
- Which Employees have badges, but aren’t in the HR system? (the question was WHY and how many employees do we have that meet this criteria)? Turns out there were multiple copies of PeopleSoft, built regionally (in different countries) – so when the data was brought together, employees on-loan from another country weren’t recognized by the local operational application!! They had trouble getting paid for their work until we disclosed a broken business process that should have synchronized the badges across the PeopleSoft instances around the world.
- Business Declared: We have only ONE financial account manager responsible for final sign-off on a rocket contract.. Yet when we looked at old data from 5 years ago, we found that the data said: 5 years ago you had as many as 7 financial account managers signing off on a rocket contract. Wouldn’t you like to know WHEN this happened? and IF it’s still happening today? (broken business operational process) – turns out, they still had a few contracts a year that had more than one financial user signing off on a single contract, they said: that cost them serious time and was a waste of money – they needed to fix this ASAP.
- Which work centers have more than one employee working at them, at the same time? Turns out, some of the physical work centers only supported a SINGLE employee at a time – but some of the shop floor workers were “doing double time”. Why? Well, the warehouse couldn’t tell them why, it just told them WHERE, and WHO. The business discovered a few reasons as to WHY: a) mentoring of younger / new hires, b) the part was so complex to build, it required a team to build it. They ended up adjusting the source system (which didn’t allow this to be assigned to more than one worker), they also built new work centers to support team work better. The Data Vault FOUND this by loading the relationships expressed in the HR system (they clocked in and out together at multiple work centers). Only a many to many was able to support this type of query.
Some notes about Lockheed Martin at the time: 159,000 Employees (at the time), 7 sectors of business, 53 companies each with their own Company President driven by their own P&L, spanning 15 countries around the world, 5 geo-based instances of SAP, 5 geo-based instances of PeopleSoft, and more… We were asked to build a central enterprise focused Cost Reporting Data Warehouse for Manufacturing, and to include: finance, contracts, sales, HR, manufacturing, Planning, operations, maintenance and support, launch logistics (Cape Canaveral and NASA), and delivery. I had a team of 3 and half (part time) people on my team, 6 months to build, and ingest 125 source systems from around the world. This was back when 10-base T networks were considered “fast” across the oceans.
In Lockheed Martin (where I designed and built the Data Vault methodology), we had 125 source systems to integrate. Everything from SAP to I2, to Oracle Financials, to JD Edwards, to Peoplesoft, to Windchill, and so on… We had a number of in-house designed operational systems like MACPAC-D from Anderson Consulting (manufacturing and cost accounting and control) version D. We had 75 source systems that all carried some form or copy of a “rocket building contract”.
Each of the source applications represented a different “version of the relationships” between, and across employees, contracts, work centers, rockets, managers, and so on. It would have been absolutely impossible to span the global enterprise (as we had source systems in different countries too), and represent a single 1 to many relationship in a data warehouse. The design would have failed from the start (and in fact that’s exactly what happened). EACH SOURCE SYSTEM HAD IT’S OWN COPY / VERSION OF THE TRUTH…
To represent them, and load the data to a data warehouse we had no choice, we were forced to be data driven in 1995. Once we moved to data driven we had a few things happen that forced our design to become flexible, scalable, and ultimately enterprise worthy:
- Many-to-Many relationships had to be designed and loaded, letting business rules around relationships be coded for detection when building data marts on the way out.
- No re-engineering was allowed simply because a new source system / application data was to be loaded.
- No or ZERO impact when a source system CHANGED it’s relationship in the operations side of the house, we simply loaded the data and reported the change.
- We were able to detect changes to operational applications by querying the data sets
Most of all, we were able to begin weighing the impact of the changes made to the operational systems – as to whether or not it was a GOOD change or a BAD change (had a negative impact on the business).
There are Diamonds in the Rough…
Understanding what’s broken is just as important as understanding what works. Running metrics across your data sets, across your operational applications, and your dirty data is just as valuable as metrics produced by clean data for trends and future forecasting. To understand how we can properly model in a data warehouse (NOT just a Data Vault), and why MANY-TO-MANY is critical, we need to take a step back and understand source application relationships. You can have either declared relationships in your data model, or data driven relationships but you cannot have both at the same time in the same set of table structures.
Operational Relationships in source systems can be viewed as follows: BY TIME, or BY GEO-INSTANCE BY TIME. The diagram below has two different label sets that illustrate these principles:
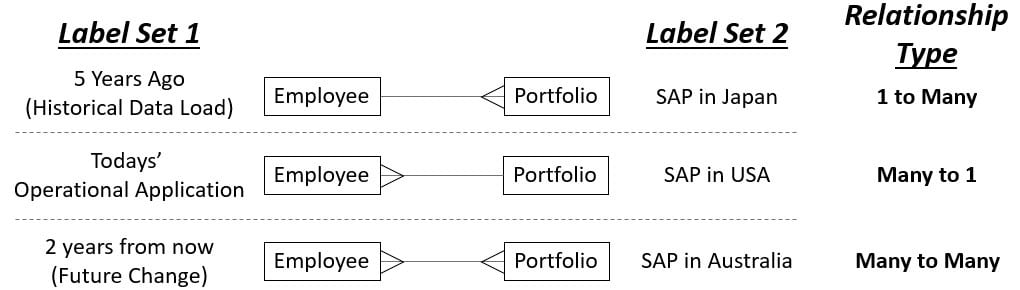
What you can see from this diagram is the following:
- LEFT SIDE LABELS: Indicate relationships that are changing over time.
- RIGHT SIDE LABELS: Indicate that a different instance in a different country (of the SAME operational application), may be customized to represent a different way of doing business based on geographic region
Some questions to ask about your data sets (if IT won’t ask them, then you SHOULD) – you should be asking IT: why can’t I discover these problems from the data warehouse you built?
- What happens to the data model when a new source system comes in, that declares a different relationship for the same data set? (ie: SAP in the USA was customized differently than SAP in Europe)
- Why do you have to re-engineer the load processes and the data model every time we change our source system?
- What happens to the dirty / broken data when the relationship is actually broken? Why can’t I run analytics on the busted data directly in my warehouse?
- What is the impact to the data warehouse (loads, queries, models) when we change the relationship in the future?
- Technically: Why are you struggling with performance against our “Data Vault”? You said we built a Data Vault, and now you’re telling me it doesn’t perform…
That last question is a bit unfair, but needs to be asked. The honest answer is: Many consultancies do not know how to properly tune queries, environments, much less Data Vault models. To which I reply: I’m happy to help. Just contact me here on the site, and we’ll see about getting you fixed up as fast as possible.
What is a Data Driven Relationship?
As it turns out, there is a difference between expressing your relationships in a data model (with primary and foreign keys), and letting your relationships be driven by the data set over time.
A Data Driven Relationship is built as a many-to-many table housing both sides of the keys, or in set math terms – the physical storage of the keys that represent the intersection of two or more sets. Storing the relationship as-is defined in the source system, over multiple points in the timeline, or across multiple geographic regions (across multiple source systems) allows the queries to ask the questions; allows the data to tell the story as to what and when the relationship was built a particular way. This means: the relationship itself is “discovered”, data driven at query time. This allows you and the BI analytics designers the freedom to explore the relationship and the relationship changes, whenever they happen.
Let’s dive a little deeper, and try to uncover why some consultants / consultancies believe that “replicating source system relationships to a data warehouse design” is a good idea. In order to understand this flawed thought process, we need to go back to the job of a data warehouse juxtaposed with the job of information delivery. Many people confuse the job of the data warehouse with the job of an analytical output. The data warehouse has a few jobs:
- To tell the business where, when and by how much it’s business processes are either broken or working as designed
- To tell the business where, when, and by how much the source data overlaps across multiple systems
The job of the information mart (delivery system, analytical output) is different: to provide clean, integrated, and accurate data that can be used for forecasting and better decision making processes. We (in the Data Vault landscape) make a distinction between the two. Because we distinguish these, we can also produce an information mart that provides the business with gap analysis capabilities. In other words: how far off our KPA’s and KPI’s are we according to the data? I think, this is rather important don’t you?
If we “leave the data sitting” in the staging area / data dump / data junkyard / landing zone because the relationship “doesn’t meet the current data warehouse design”, then we cannot report these metrics. If we don’t ingest the “good data, the bad data, and the ugly data” (if all we ingest is cleansed, quality checked data) then we are sweeping all the broken business debt under the rug, and telling IT to be the bottleneck (IT: go create the load processes that only allow clean data in)…. None of this is very good, but I digress.
By doing something simple: allowing bad data (broken data, broken relationships, busted referential integrity), by designing a solution in the data warehouse that contains a many-to-many, we effectively change our data warehouse from being “architecture driven” to being “data driven.” The Data Vault model leverages Link structures for this, and now – we can run the queries / answer the questions we posed above.
To be data driven means YOU have to learn to write the business rules (queries) that determine what is right / accurate TODAY versus YESTERDAY versus TOMORROW. Or determine what is right by query logic across multiple source systems. To allow the data to load, the only design that is resilient enough is to construct a MANY-TO-MANY link structure. Which is exactly what the Data Vault model states in it’s standards. Consulting firms / consultants who don’t understand this, should not be building data warehouses for your company, as they do not understand what it means to be a data driven enterprise.
Summarizing The Obvious…
Building Many-to-Many relationships switch your data warehouse model from design driven to data driven. They provide consistency and resiliency without needing to re-engineer just to absorb another source. They tell stories about the relationships over different time points and different geographical regions. Consultants and consultancies who claim otherwise will continue to build inflexible, brittle data warehousing solutions.
One thing I forgot to mention: the nay-sayers claim many-to-many join performance in the Data Vault is always a problem. This is only true if they haven’t designed the Data Vault model properly, or have no clue about performance tuning big data solutions. I’ve been performance tuning systems between 300 Terabytes and 3 Petabytes for years (some of the largest commercial systems around), and if you really want to unlock these secrets, you can sign up for CDVP2 classes, bring one of my authorized trainers (or me) in to assess and help. Or you can sign up for my new micro-course on DRIVING KEY. I unlock the performance and tuning secrets of SQLServer with Data Vault, along with the many-to-many secrets of performant joins in this new course.
In the end, there are business values in broken data metrics. They can tell you where your business processes are broken, and by what percentage (how badly broken is it?) My final question to you is: Can you really afford the re-engineering of a design solution in your data warehouse just because you bring in historical data, or yet another operational data source?
Questions? use the CONTACT US form, happy to chat with you over a zoom meeting about these or other topics.





