


Centralized vs Decentralized Architecture
By Mark Budzinski
Centralized vs Decentralized Architecture is a topic we have been discussing in our podcast and blogs lately. We often like to frame the discussion of centralization as a war, an either/or focused on the versus in the middle. Because of this, the flaws of both sides are brought to the forefront: on the centralized extreme is authoritative governance with every branch equally controlled, but missing vital nuance dependent upon the department, needs, and uses of data.
On the decentralized extreme is the devolvement into silos as tall as the sky, with unneeded competitiveness and breakdowns of communication and efficiency.
Rather than picking a side and hoping for the best, both extremes can and should be balanced in the middle, with business and data rules where necessary, but also allowing for freedom as different departments within an organization work together. This is yet another instance where Data Vault 2.0, when fully utilized, makes achieving such a balance, much easier. Lets first tackle the two data architectures, centralized and decentralized.
We see opposing forces in chemistry, in the cases in which one hydrogen atom shares some electrons with fluorine, or nitrogen, or an oxygen atom, to create a “covalent bond.”
We see it in magnetism wherein north and south poles are attracted to each other, while the same poles repel each other.
We also see it in politics when groups of people form tightly knit tribes grounded in common belief systems and are wary of those who share different views. Why, even Cupid reports that when love is in the air, “opposites attract.”
There remain forces across all these examples, if left to their own pulsations, will drive the system in play towards harmony, or alternatively, toward chaos. In data management, where we are required to deal with a seemingly infinite set of conditions, getting the balance right is an endeavor that can look daunting.
Centralized vs Decentralized Architecture
Over the last few podcast episodes, Unlocking the Vault, Dan and Cindi have framed the discussion of opposing forces in the paradigm of “centralized vs. decentralized.”
Like magnets, the poles of these approaches are prone to behave in a natural rhythm.
Opposites do indeed attract. The challenge for us, then, is to keep competing forces (usually caused by human intervention) under control, and do what we can to let nature take its course.
In a Data Vault architecture, it is not uncommon to separate the people, as well as the code, into distinct constituencies. The Raw Vault is best built by those professionals who are studied and certified in the art forms of business-focused data integration modeling and persisting auditable data on behalf of an organization.
Authorized Training Providers (ATPs), of course, provide the means. Accomplished data engineers provide the way.
The actions required to build a Raw Vault are largely centralized in its credo.
We recall that one of the axiomatic benefits of a Data Vault approach is to absorb new source data as fast as the source data cometh. We add tables, rather than rebuild them. We track history data cleanly, without confusion or compromise. The objectives are cohesive. Capture all the data we need. Stand ready to prove where data comes from, and where it goes. Let’s give the regulatory authorities what they want, and send them away satisfied.
Meanwhile, seemingly 10 light-years away from the data engineers reside the managers responsible for operating the enterprise.
They make assumptions about data, generally. Assumption 1: whatever is needed is available. Assumption 2: whatever is available is accurate. And no, these are not crazy, unreasonable assumptions, as far as assumptions go.
Imagine your airline pilot shuttling you to a business meeting challenging the data in the cockpit, or over the radio from the tower. *Of course* the data is available and the data is right; we’re flying a plane, here.
But unlike flying a plane, the business people in most organizations expect to manipulate data in some way. And again, it’s a reasonable expectation. What is happening? Why is it happening? Is there correlation? Causation?
How do we take the appropriate management action to affect the future positively? And when we do take action…did it work? It’s a constant loop of questions, answers, and more questions.
And what is the tenet underpinning all this data manipulation and analysis? Decentralized, bespoke service.
So here we are, with two magnetic poles very much looking after their own agendas, goals, and needs.
They are opposite, and they do indeed attract via macro forces. The two are codependent; we can’t have one without the other. We can’t have success without both operating in harmony.
The natural rhythm for a data savvy organization is to constantly nurture the attraction. Business people should only manipulate data that affects *them* and not others down the hall in a complementary role.
Do not mess with the corporate data. Do not build things that are untraceable to governed, centralized policy for data access, security, and data quality.
The Raw Vault guys should stay out of the analysis business as relates to capturing the auditable, raw data. Don’t try to predict business applications of the data at this level. Keep it simple.
But how do we make sure that these poles attract as intended in the pursuit of harmony and balance? The answer is derived in the other two architectural components of a Data Vault: the Business Vault and the Information Mart. Each play a stunning role to accelerate the forces for attraction (see Figure 1).
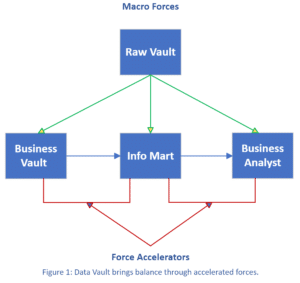
The Business Vault, when done right, serves as a pulley to take data from a Raw Vault, and bring disproportionate, accelerated value of that data in a business context.
It’s not simply a matter of “passing data through” from one layer to another. Rather, data starts to take on business rules, denormalizations, calculations, and other query assistance functions. We are *pulling* business value from the Raw Vault. Business Vault tables can be refreshed once their dependent Raw Vault tables are updated.
At this stage, have we provided data to the business people hungry for custom manipulation, analysis, and reporting? No. And those organization who *think* they have provided this value are making it hard on everybody.
Decrees to management to “take the Data Vault training,” misses the point. We don’t need, and certainly don’t want our business managers distracted with learning the ins-and-outs of Data Vault lingo. This kind of action perverts the natural polar forces that are in play across the organization.
Rather, let’s now create a pulley to accelerate the delivery of data to business managers in a form that *they* are looking for it.
It’s a network information marts, modeling as dimensional tables or whatever outcome the business requires, that fit the needs of the analysts.
If the pulley works as intended, there’s no reason for the business team to go off on their own and build their own pseudo-data-platform. Repellant forces should be put to bed; let the Data Vault architecture work as intended.
The Centralized vs Decentralized Architecture Debate
So, in our debate about decentralized vs. centralized, the answer isn’t either/or. It’s both. Don’t think of it as a fight between centralized vs decentralized architecture. Raw Vault is a logically centralized architectural component.
Sure, one can spread out the data across a greater set of real estate, but it hangs together with centralized rigor. Basic governance demands it. And the business people? They are, by definition, a decentralized sort.
At first glance, it’s easy to be duped that Raw Vault designers and business managers have different, repelling agendas. I mean, they couldn’t behave more differently when they come to the office. But here, in truth, opposites really do attract.
They are complementary ends of a data management system that demands forces of attraction to prevail in order to be operationally sound.
Thankfully, we have the Business Vault and the Information Mart. They each serve as accelerators to make sure that the forces in play are pulling towards harmony, and ultimately, for good.




