

Building a Snowflake Data Vault
In this day and age, with the ever-increasing availability and volume of data from many types of sources such as IoT, mobile devices, and weblogs, there is a growing need, and yes, demand, to go from batch load processes to streaming or “real-time” (RT) loading of data.
Businesses are changing at an alarming rate and are becoming more competitive all the time. Those that can harness the value of their data faster to drive better business outcomes will be the ones to prevail.
One of the benefits of using the Data Vault 2.0 architecture is that it was designed from inception not only to accept data loaded using traditional batch mode (which was the prevailing mode in the early 2000s when Dan introduced Data Vault) but also to easily accept data loading in real or near-realtime (NRT). Most professionals try to figure out how to integrate a real-time data vault in snowflake these days.
In the early 2000s, that was a nice-to-have aspect of the approach and meant the methodology was effectively future-proofed from that perspective. Still, few database systems had the capacity to support that kind of requirement. Today, RT or at least NRT loading is almost becoming a mandatory requirement for modern data platforms. Granted, not all loads or use cases need to be NRT, but most forward-thinking organizations need to onboard data for analytics in an NRT manner.
Those who have been using the Data Vault approach don’t need to change much other than figure out how to engineer their data pipeline to serve up data to the Data Vault in NRT. The data models don’t need to change; the reporting views don’t need to change; even the loading patterns don’t need to change. (NB: For those that aren’t using Data Vault already, if they have real-time loading requirements, this architecture and method might be worth considering.)
Real-Time Data Vault in Snowflake
There have been numerous blog posts, user groups, and webinars over the last few years, discussing the best practices and customer success stories around implementing real-time Data Vaults in Snowflake. So the question now is how do you build a Data Vault in Snowflake that has real-time or near real-time data streaming into it.
Luckily, streaming data is one of the use-cases that Snowflake was built to support, so we have many features to help us achieve this goal. The rest of this article will give you the details on one way you might build a real-time Data Vault feed on Snowflake.
Reference Architecture
Let’s start with the overall architecture to put everything in context.
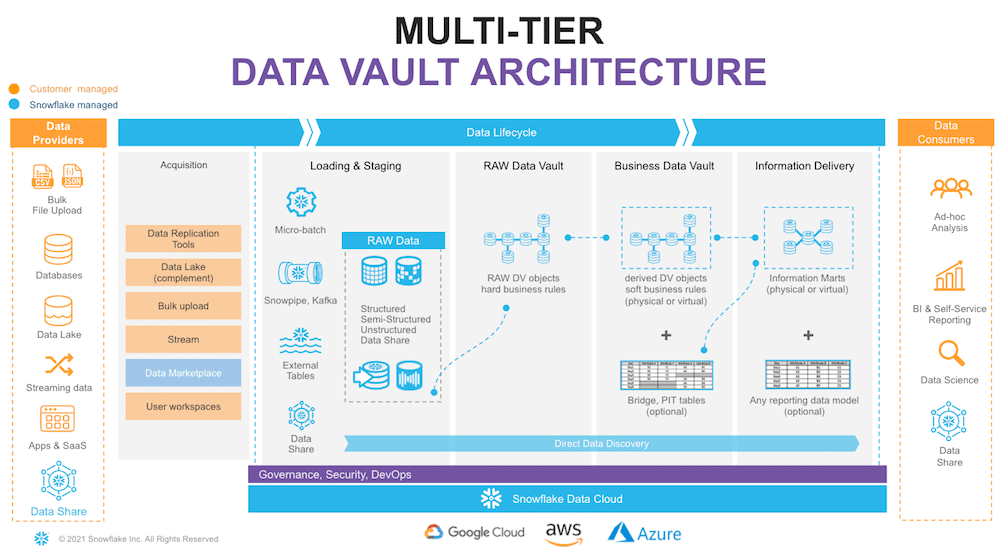
On the very left of figure 1, we have a list of data providers that typically include a mix of existing operational databases, old data warehouses, files, lakes, and 3rd party apps. There is now also the possibility to leverage Snowflake Data Sharing/Marketplace as a way to tap into new 3rd party data assets to augment your data set.
On the very right, we have our ultimate data consumers: business users, data scientists, IT systems, or even other companies you decided to exchange your data with. Architecturally, we will split the data lifecycle into the following layers:
Data Acquisition: extracting data from source systems and making it accessible for Snowflake.
Loading & Staging: moving the source data into Snowflake. For this, Snowflake has multiple options, including batch load, external tables, and Snowpipe (their managed service for onboarding streaming data).
Snowflake allows you to load and store structured and semi-structured in the original format while automatically optimizing the physical structure for efficient query access. The data is immutable and should be stored as received from the source with no content changes. From a Data Vault perspective, functionally, this layer is also responsible for adding technical metadata (record source, load date timestamp, etc.) and calculating business keys.
Raw Data Vault: a Data Vault model with no soft business rules or transformations applied (only hard rules are allowed) loading all records received from a source.
Business Data Vault: Data Vault objects with soft business rules applied. The raw Data Vault data is getting augmented by the intelligence of the system. It is not a copy of the raw data vault but rather a sparse addition with, perhaps, calculated satellites, mastered records, or maybe even commonly used aggregations.
This could also optionally include PIT and Bridge tables to simplify access to the data’s bi-temporal view. From a Snowflake perspective, raw and business data vaults could be separated by object naming convention or represented as different schemas or even different databases.
Information Delivery: a layer of consumer-oriented models. This could be implemented as a set (or multiple sets) of views. It is common to see the use of dimensional models (star/snowflake) or denormalized flat tables (for data science or sharing).
Still, it could be any other modeling stye (e.g., unified star schema, supernova, key-value, document object model, etc.) that fits best for your data consumer. Snowflake’s scalability will support the required speed of access at any point of this data lifecycle. You should consider Business Vault and Information Delivery objects materialization as optional. This specific topic (virtualization) is going to be covered later in this article.
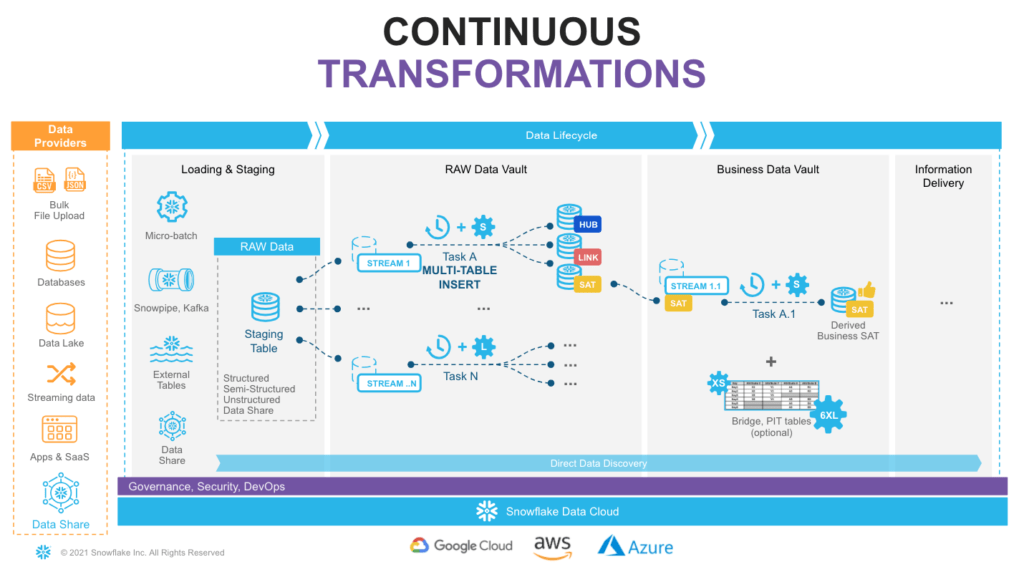
Snowflake supports multiple options for engineering data pipelines. In this post, we will show one of the most efficient ways to implement incremental NRT integration leveraging Snowflake Continuous Data Pipelines. Let’s take a look at the architecture diagram (figure 2) to understand how it works.
Snowflake has a special stream object that tracks all data changes on a table (inserts, updates, and deletes). This process is 100% automatic and, unlike traditional databases, will never impact the speed of data loading. The changelog from a stream is automatically ‘consumed’ once a successfully completed DML operation uses the stream object as a source.
So, loading new data into a staging table would immediately be reflected in a stream showing the ‘delta’ that requires processing.
“Tasks” is the second component we are going to use. It is a Snowflake managed data processing unit that will wake up on a defined interval (e.g., every 1-2 min) and check if there is any data in the associated stream. If so, run SQL to push it to the Raw Data Vault objects. Tasks could be arranged in a tree-like dependency graph, executing child tasks when the predecessor has finished its part.
Last but not least, following Data Vault 2.0 best practices for NRT data integration (to load data in parallel), we will use Snowflake’s multi-table insert (MTI) inside tasks to populate multiple Raw Data Vault objects by a single DML command. (Alternatively, you can create multiple streams & tasks from the same table in a stage to populate each data vault object by its own asynchronous flow.)
Next step, you assign tasks to one or many virtual warehouses. This means you always have enough compute power (XS to 6XL) to deal with any size workload. Simultaneously, the multi-cluster virtual warehouse option will automatically scale-out and load balance all the tasks as you introduce more hubs, links, and satellites to your vault.
As your raw vault is updated, streams can then be used to propagate those changes. Business Vault objects (such as derived Sats, PITS, or Bridges, if needed) in the next layer. This setup can be repeated to move data through all the layers in small increments very quickly and efficiently. All the way until it is ready to be accessed by data consumers (if materialization of the data is required for performance).
Following this approach will result in a hands-off production data pipeline that feeds your Data Vault architecture. Here’s an example of a build for a real-time data vault in snowflake.
Code Example – Real-Time Data Vault in Snowflake
Let’s demonstrate some of the concepts we just talked about:
1. Create staging objects
We are going to create a staging table and a stream for order data.
CREATE OR REPLACE TABLE stg_orders
(
o_orderkey NUMBER
, o_custkey NUMBER
, o_orderstatus STRING
, o_totalprice NUMBER
, o_orderdate DATE
, o_orderpriority STRING
, o_clerk STRING
, o_shippriority NUMBER
, o_comment STRING
, filename STRING NOT NULL
, file_row_seq NUMBER NOT NULL
, ldts STRING NOT NULL
, rscr STRING NOT NULL
);
CREATE OR REPLACE STREAM stg_orders_strm ON TABLE stg_orders;
2. Set up automatic data ingestion
Snowflake documentation covers the specifics of creating external stages, Snowpipe and its auto_ingest setup in great detail for all available cloud providers. We can start dropping files into the bucket at the end of this step, and data would automatically load into the staging table, adding additional technical metadata such as file name, load timestamp, etc.
| CREATE OR REPLACE STAGE orders_data
URL=’s3://my_bucket/orders/’ STORAGE_INTEGRATION = my_s3_storage_integration; FILE_FORMAT = (TYPE = CSV); CREATE OR REPLACE PIPE stg_orders_pp AUTO_INGEST = TRUE AS COPY INTO stg_orders FROM ( SELECT $1,$2,$3,$4,$5,$6,$7,$8,$9 , metadata$filename , metadata$file_row_number , CURRENT_TIMESTAMP() , ‘Orders System’ FROM @orders_data ); |
3. Derive business keys
This example demonstrates how views can be used between Staging objects(a stream or a table) and the raw data vault (RDV) to centralize business keys derivation logic. Such a technique allows incrementally introducing new keys for new RDV objects without re-materializing historical data. Also, see how the ARRAY_CONSTRUCT function can simplify code, automatically adding a delimiter character when concatenation of multiple columns is required.
| CREATE OR REPLACE VIEW stg_order_strm_outbound AS
SELECT src.* ——————————————————————– — derived business key ——————————————————————– , MD5(UPPER(TRIM(o_orderkey))) md5_hub_order , MD5(UPPER(TRIM(o_custkey))) md5_hub_customer , MD5(UPPER(ARRAY_TO_STRING(ARRAY_CONSTRUCT( TRIM(o_orderkey) , TRIM(o_custkey) ), ‘^’))) AS md5_lnk_customer_order , MD5(UPPER(ARRAY_TO_STRING(ARRAY_CONSTRUCT( TRIM(o_orderstatus) , TRIM(o_totalprice) , TRIM(o_orderdate) , TRIM(o_orderpriority) , TRIM(o_clerk) , TRIM(o_shippriority) , TRIM(o_comment) ), ‘^’))) AS order_hash_diff FROM stg_orders_strm src ; |
4. Load into Raw Data Vault
This MTI operation populates the orders hub, satellite, and the customer-order link for the new data available in the stream. As you can see, this code is embedded in the task object that automatically checks the stream for new data and will resume the virtual warehouse only when there is work to do.


Views for Agile Reporting – Real-time Data Vault in Snowflake
One of the great benefits of having the compute power from Snowflake is that now it is totally possible to have most of your business vault and information marts in a Data Vault architecture be built exclusively from views.
Numerous customers are using this approach in production today. There is no longer a need to argue that there are “too many joins” or that the response won’t be fast enough. The elasticity of the Snowflake virtual warehouses combined with our dynamic optimization engine has solved that problem. (For more details, see this post.)
If you really want to deliver data to the business users and data scientists in NRT, in our opinion, using views is the only option. Once you have the streaming loads built to feed your Data Vault, the fastest way to make that data visible downstream will be “views.”
Using views allows you to deliver the data faster by eliminating any latency incurred by having additional ELT processes between the Data Vault and the data consumers downstream.
All the business logic, alignment, and formatting of the data can be in the view code. That means fewer moving parts to debug and reduces the storage needed as well.
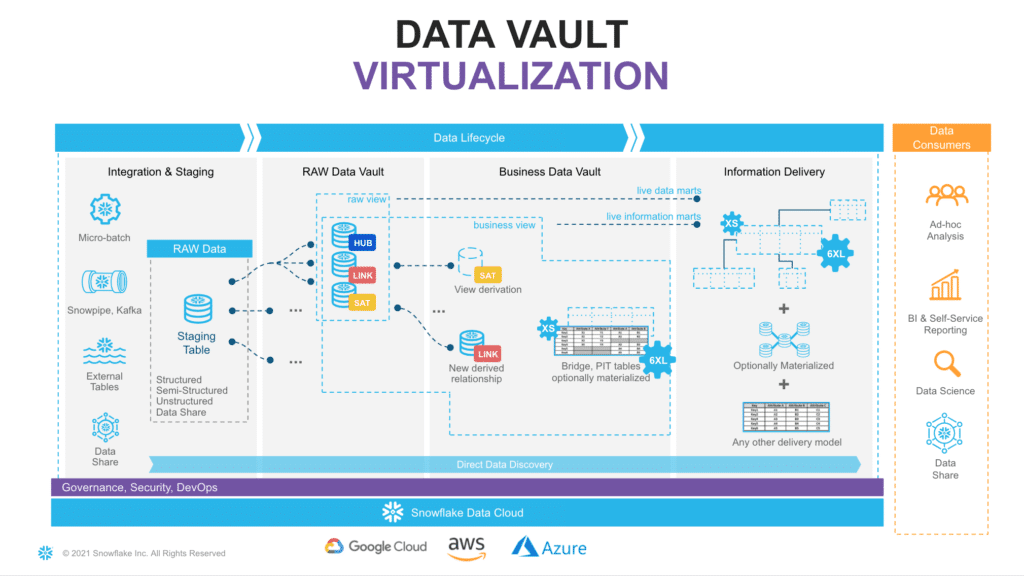
Looking at the diagram (Figure 3), you will see an example of how virtualization could fit in the architecture. Here, solid lines are representing physical tables and dotted lines – views. You incrementally ingest data into Raw Data Vault, and all downstream transformations are applied as views. From a data consumer perspective, when working with a virtualized information mart, the query always shows everything known by your Data Vault, right up to the point the query was submitted.
With Snowflake, you have the ability to provide as much compute as required, on-demand, without a risk of causing performance impact on any surrounding processes and pay only for what you use. This makes the materialization of transformations in layers like Business Data Vault and Information delivery an option rather than a must-have. Instead of “optimizing up front,” you can now decide based on the usage pattern characteristics, such as frequency of use, type of queries, latency requirements, the readiness of the requirements, etc.
Many modern data engineering automation frameworks are already actively supporting the virtualization of logic. Several tools offer a low-code or configuration-like ability to switch between materializing an object as a view or a physical table, automatically generating all required DDL & DML. This could be applied to specific objects, layers, or/and be environment-specific. Even if you start with a view, you can easily refactor using a table if user requirements evolve.
As said before, virtualization is not only a way to improve time-to-value and provide near real-time access to the data, given the scalability and workload isolation of Snowflake. Virtualization also is a design technique that could make your Data Vault excel: minimizing cost-of-change, accelerating the time-to-delivery, and becoming an extremely agile, future-proof solution for ever-growing business needs.
As a quick example of such an approach, here is how the enrichment of customer descriptive data could happen in Business Data Vault, connecting data received from source with some reference data.
| CREATE OR REPLACE VIEW l20_bdv.sat_customer_bv
AS SELECT rsc.md5_hub_customer , rsc.ldts , rsc.c_name , rsc.c_address , rsc.c_phone , rsc.c_acctbal , rsc.c_mktsegment , rsc.c_comment , rsc.nationcode , rsc.rscr — derived , rrn.n_name nation_name , rrr.r_name region_name FROM l10_rdv.sat_customer rsc LEFT OUTER JOIN l10_rdv.ref_nation rrn ON (rsc.nationcode = rrn.nationcode) LEFT OUTER JOIN l10_rdv.ref_region rrr ON (rrn.regioncode = rrr.regioncode) ; |
As said before, virtualization is not only a way to improve time-to-value and provide near real-time access to the data, given the scalability and workload isolation of Snowflake, virtualization also is a design technique that could make your Data Vault excel: minimizing cost-of-change, accelerating the time-to-delivery and becoming an extremely agile, future proof solution for ever-growing business needs.
Conclusion – Real-time Data Vault in Snowflake
The simplicity of engineering, openness, scalable performance, enterprise-grade governance enabled by the core of the Snowflake platform are now allowing teams to focus on what matters most for the business and build truly agile collaborative data environments. Teams can now connect data from all parts of the landscape until there are no stones left unturned. They are even tapping into new datasets via live access to the Snowflake Data Marketplace.
The Snowflake Data Cloud combined with a Data Vault 2.0 approach allows teams to democratize access to all their data assets at any scale. We can now easily derive more and more value through insights and intelligence, day after day, bringing businesses to the next level of being truly data-driven. Real-time data vault in snowflake helps bring data along with a beefy security layer.
Delivering more usable data faster is no longer an option for today’s business environment. Using the Snowflake platform, combined with the Data Vault 2.0 architecture, it is now possible to build a world-class analytics platform that delivers data for all users in near real-time.
About the Authors
Dmytro Yaroshenko
EMEA Field CTO at Snowflake helps organizations apply “the art of the possible” to digital transformation plans. Agile Data Warehouse and Data Vault Evangelist, with 17+ years dealing with good (and bad) solutions for data challenges. Good guy.
Kent Graziano
Kent Graziano (AKA The Data Warrior) is the Chief Technical Evangelist for Snowflake and an award-winning author, speaker, and trainer. He is an Oracle ACE Director (Alumni), Knight of the OakTable Network, a certified Data Vault Master and Data Vault 2.0 Practitioner (CDVP2), and expert solution architect with over 35 years of experience, including more than 25 years of designing advanced data and analytics architectures (in multiple industries).
Kent is an internationally recognized expert in cloud and agile data design. He has written numerous articles, authored three Kindle books, co-authored four other books, and has given hundreds of presentations nationally and internationally. Kent was co-author of the first book on Data Vault and the Technical Editor for Super Charge Your Data Warehouse. You can follow Kent on Twitter @KentGraziano Thank you for reading our post on building a real-time data vault in snowflake.




